AWS DL1 Quick Start Guide
On this Page
AWS DL1 Quick Start Guide¶
This document provides instructions to set up an Amazon EC2 DL1 instance and start training a PyTorch model on the Intel® Gaudi® AI accelerator.
Prerequisites¶
AWS account - https://aws.amazon.com.
us-west-2 or us-east-1 regions which is where AWS EC2 DL1 instances are available.
Create an EC2 Instance¶
Follow the below step-by-step instructions to launch an EC2 DL1 instance.
Initiate Instance Launch¶
Open the Amazon EC2 Launch Console.
In Name and tags, enter a name for the AMI. In this example, we chose
habana-quick-startfor the name.In Application and OS Images, search for
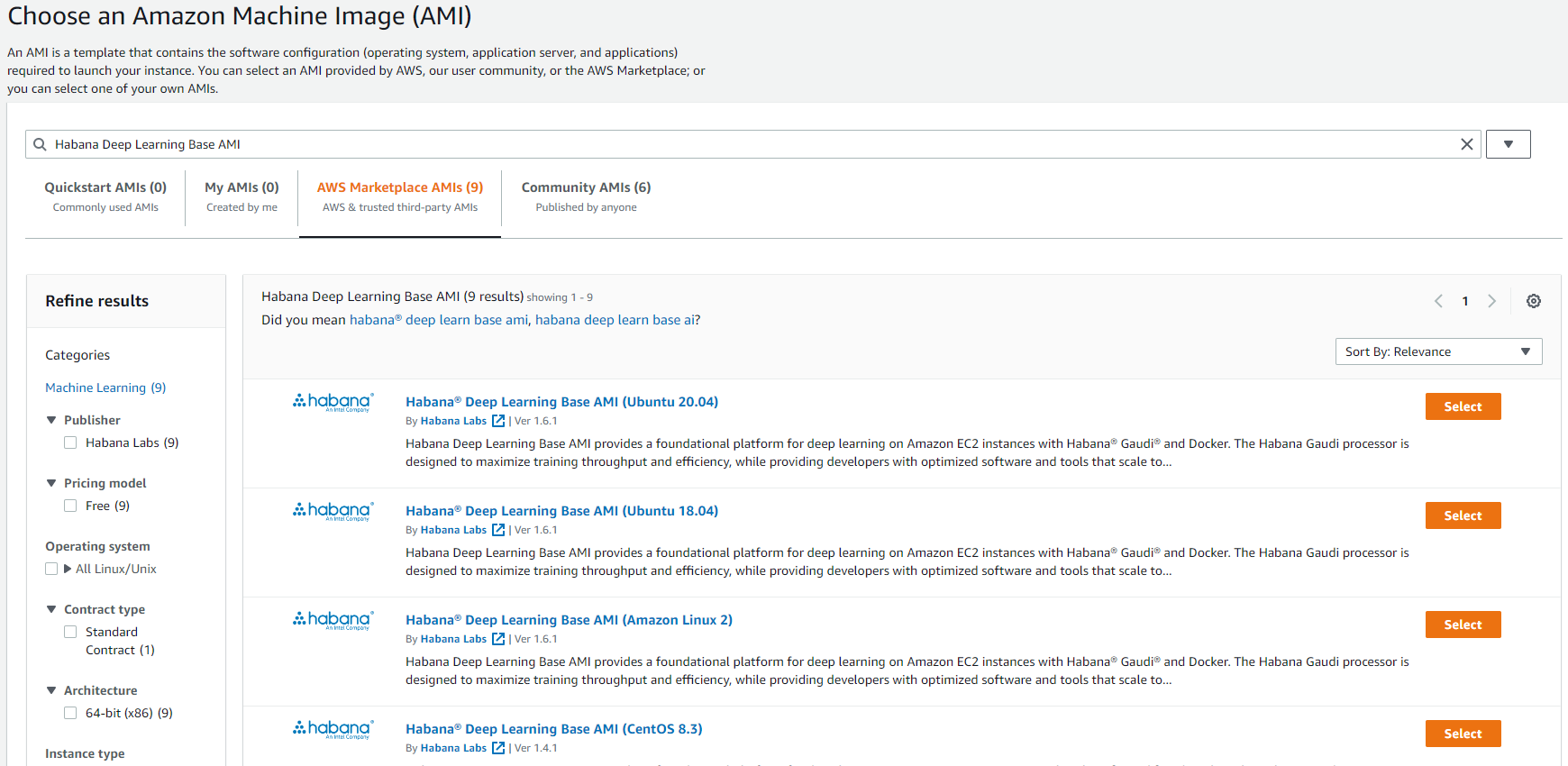
Habana Deep Learning Base AMIand choose the desired operating system. These are located in the AWS Marketplace AMIs:
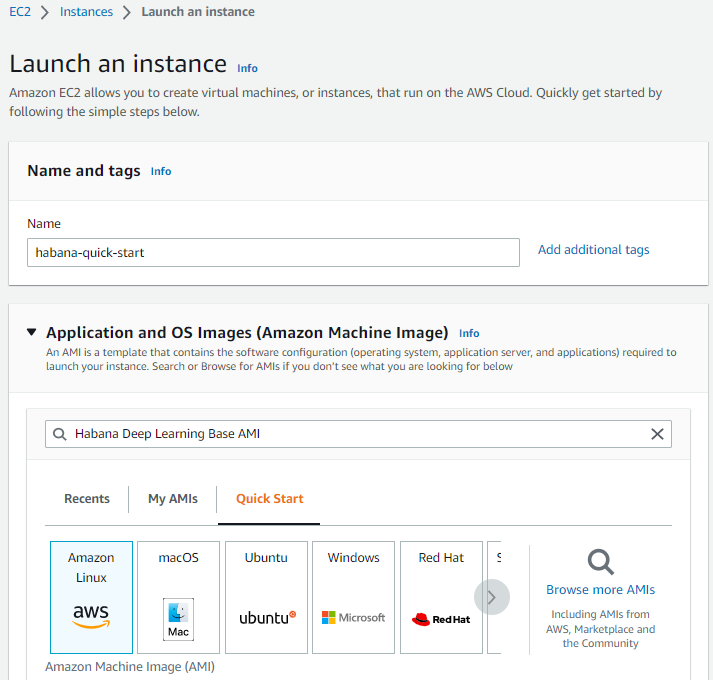
Click on the Select button:
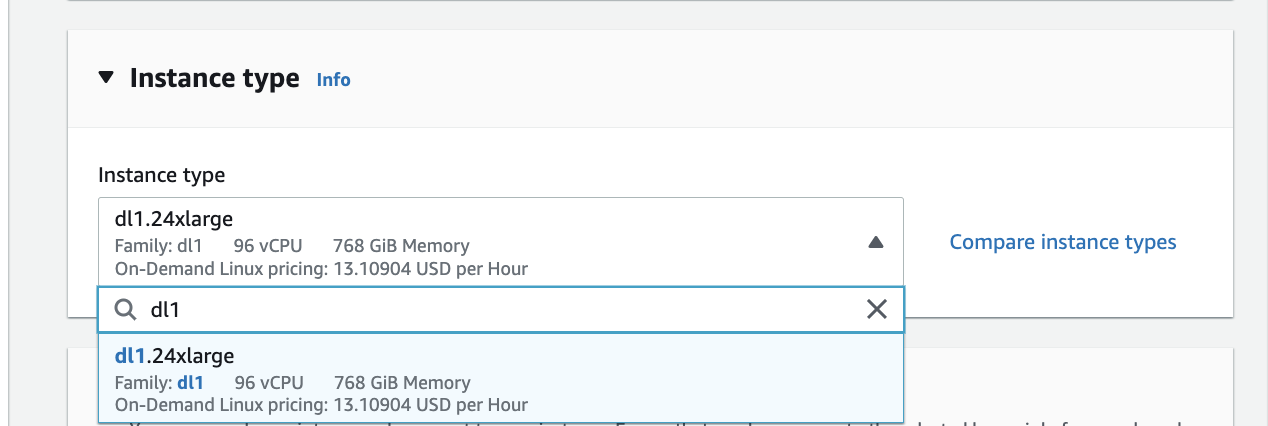
Select Key Pair¶
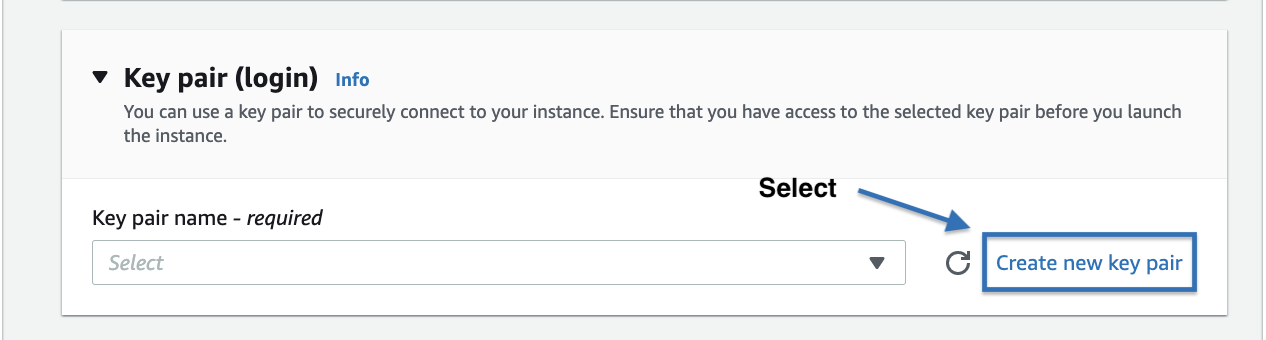
If you have an existing key pair, select the key pair to be used for accessing the instance with ssh from the dropdown menu or use a new key pair by clicking on the Create new key pair button.
Configure Network¶
Make sure to configure your network settings according to your setup. To keep this example simple, we chose a network open to the public. It is recommended you set the security group rules that allow access from known IP addresses only.

Configure Storage¶
Choose the desired storage size for your EC2 instance. In this example, we used 500GB.
Review¶
Verify your configuration is correct and select the Launch instance button.
You have now launched an EC2 Instance.
Note
When launching a Base AMI for the first time, the subscription process may take a while.
Connect to your Instance¶
Using ssh you can connect to the instance that you launched. Make sure to update the following values to run the below command:
ssh -i ~/.ssh/"key_pair.pem" ubuntu@"PUBLIC_DNS"
key_pair.pem -- Use the key produced in Select Key Pair
PUBLIC_DNS -- You can find this parameter under the Public IPV4 DNS section in the instance details
Alternatively, when selecting the instance in your AWS Console, you can click on the Connect button and use the commands tailored for your instance under the SSH client tab.
For more details, please refer to Connect to your Linux instance using an SSH Client Guide.
Start Training a PyTorch Model on Gaudi¶
Run the Intel Gaudi Docker image:
docker run -it --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --net=host --ipc=host vault.habana.ai/gaudi-docker/1.18.0/ubuntu22.04/habanalabs/pytorch-installer-2.4.0:latest
Clone the Model References repository inside the container that you have just started:
git clone https://github.com/HabanaAI/Model-References.git
Move to the subdirectory containing the hello_world example:
cd Model-References/PyTorch/examples/computer_vision/hello_world/
Update PYTHONPATH to include Model References repository and set PYTHON to Python executable:
export PYTHONPATH=$PYTHONPATH:Model-References export PYTHON=/usr/bin/python3.8
Note
The Python version depends on the operating system. Refer to the Support Matrix for a full list of supported operating systems and Python versions.
Training on a Single Gaudi¶
Run training on single Gaudi in BF16 with autocast enabled:
$PYTHON mnist.py --batch-size=64 --epochs=1 --lr=1.0 \
--gamma=0.7 --hpu --autocast
============================= HABANA PT BRIDGE CONFIGURATION ===========================
PT_HPU_LAZY_MODE = 1
PT_HPU_RECIPE_CACHE_CONFIG =
PT_HPU_MAX_COMPOUND_OP_SIZE = 9223372036854775807
PT_HPU_LAZY_ACC_PAR_MODE = 1
PT_HPU_ENABLE_REFINE_DYNAMIC_SHAPES = 0
---------------------------: System Configuration :---------------------------
Num CPU Cores : 96
CPU RAM : 784288608 KB
------------------------------------------------------------------------------
Train Epoch: 1 [0/60000.0 (0%)] Loss: 2.296875
Train Epoch: 1 [640/60000.0 (1%)] Loss: 1.546875
***
Train Epoch: 1 [58880/60000.0 (98%)] Loss: 0.020264
Train Epoch: 1 [59520/60000.0 (99%)] Loss: 0.001488
Total test set: 10000, number of workers: 1
* Average Acc 98.500 Average loss 0.046
Distributed Training on 8 Gaudis¶
Run training on eight Gaudis in BF16 with autocast enabled:
mpirun -n 8 --bind-to core --map-by slot:PE=6 \
--rank-by core --report-bindings \
--allow-run-as-root \
$PYTHON mnist.py \
--batch-size=64 --epochs=1 \
--lr=1.0 --gamma=0.7 \
--hpu --autocast
| distributed init (rank 0): env://
| distributed init (rank 3): env://
| distributed init (rank 5): env://
| distributed init (rank 6): env://
| distributed init (rank 4): env://
| distributed init (rank 7): env://
| distributed init (rank 1): env://
| distributed init (rank 2): env://
============================= HABANA PT BRIDGE CONFIGURATION ===========================
PT_HPU_LAZY_MODE = 1
PT_HPU_RECIPE_CACHE_CONFIG =
PT_HPU_MAX_COMPOUND_OP_SIZE = 9223372036854775807
PT_HPU_LAZY_ACC_PAR_MODE = 1
PT_HPU_ENABLE_REFINE_DYNAMIC_SHAPES = 0
---------------------------: System Configuration :---------------------------
Num CPU Cores : 96
CPU RAM : 784288608 KB
------------------------------------------------------------------------------
Train Epoch: 1 [0/7500.0 (0%)] Loss: 2.328997
Train Epoch: 1 [640/7500.0 (9%)] Loss: 1.159214
Train Epoch: 1 [1280/7500.0 (17%)] Loss: 0.587595
Train Epoch: 1 [1920/7500.0 (26%)] Loss: 0.370976
Train Epoch: 1 [2560/7500.0 (34%)] Loss: 0.295102
Train Epoch: 1 [3200/7500.0 (43%)] Loss: 0.142277
Train Epoch: 1 [3840/7500.0 (51%)] Loss: 0.130573
Train Epoch: 1 [4480/7500.0 (60%)] Loss: 0.138563
Train Epoch: 1 [5120/7500.0 (68%)] Loss: 0.101324
Train Epoch: 1 [5760/7500.0 (77%)] Loss: 0.135026
Train Epoch: 1 [6400/7500.0 (85%)] Loss: 0.055890
Train Epoch: 1 [7040/7500.0 (94%)] Loss: 0.101984
Total test set: 10000, number of workers: 8
* Average Acc 97.862 Average loss 0.067
Now you have successfully launched a Gaudi-based EC2 DL1 instance and trained a simple PyTorch model on Gaudi. Now you can start training your own models on HPU.