Optimize Inference on PyTorch
On this Page
Optimize Inference on PyTorch¶
Inference workloads require optimization as they are more prone to host overhead. Since an inference step consumes less computation than a training step and is usually executed with smaller batch sizes, host overhead is more likely to increase throughput and reduce latency.
This document describes how to apply the below optimization methods to minimize host overhead and improve inference performance.
Set CPU Setting to Performance¶
BIOS Configuration Requirement for CPU Frequency Scaling
To enable the operating system to manage CPU performance states dynamically, the system BIOS must expose and allow control over CPU frequency scaling features.
Specifically, the BIOS must support ACPI CPU frequency scaling interfaces and not restrict access to performance states (P-states) or governors. This ensures
that the OS can read and modify the CPU frequency governor settings via cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor. Without proper BIOS support,
this interface may be unavailable or return errors, preventing the OS from applying desired power or performance policies.
The below is an example of setting the CPU to performance for Ubuntu:
#Get setting:
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
#Set setting:
echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
Note
The CPU settings must be updated on bare metal before starting the container.
Update CPU Settings¶
This section describes how to update CPU settings on Gaudi 3 using Sapphire and Granite Rapids to optimize performance.
Sapphire and EMR Rapids - 4th and 5th Gen Xeon® Processors
Set Energy Perf BIAS:
wrmsr -a 0x1b0 0x0
Set the Core Frequency (HWP):
wrmsr -a 0x774 0x2708
Granite Rapids - 6th Gen Xeon® Processor
Note
When using a Supermicro SYS-822GA-NGR3 system, update the BIOS to version 1.3 or newer to access the BIOS settings below.
Enumerated lists that are auto-numbered start with
#..
Disable SubNUMA in BIOS by navigating to Advanced → Chipset Configuration → Uncore Configuration → SNC [Disabled].
Disable the C6 state:
Note
The C6P state may not be supported on all systems. To view the available states, run the following:
cat /sys/devices/system/cpu/cpu*/cpuidle/state*/name
echo 1 | tee /sys/devices/system/cpu/cpu*/cpuidle/state2/disable
Disable C1 to C1E Promotion by navigating to Advanced → CPU Configuration → Advanced Power Management Configuration → CPU C State Control → C1 to C1E Promotion [Disabled].
Disable ACPI C6x Enumeration by navigating to Advanced → CPU Configuration → Advanced Power Management Configuration → CPU C State Control → ACPI C6x Enumeration [Disabled].
Set Package C State by navigating to Advanced → CPU Configuration → Advanced Power Management Configuration → Package C State Control → Package C State [C0/C1 state].
Set Latency Optimized Mode (LOM). This can be done either by cloning Intel® PCM API or in BIOS:
cd ~ git clone --recursive https://github.com/intel/pcm cd pcm git submodule update --init --recursive mkdir build cd build cmake .. cmake --build . sudo cp ./bin/pcm-tpmi /usr/local/bin/pcm-tpmi cd ~/pcm/scripts sudo bash ./bhs-power-mode.sh --latency-optimized-mode
For more details, see Building PCM Tools.
Navigate to Advanced → CPU Configuration → Advanced Power Management Configuration → Latency Optimized Mode [Enabled].
Set Energy Perf BIAS:
echo 0 | sudo tee /sys/devices/system/cpu/cpu*/power/energy_perf_bias
Disable Workload Profile by navigating to Advanced → CPU Configuration → Advanced Power Management Configuration → Workload Profile [Disabled].
Configure Power Performance Tuning by navigating to Advanced → CPU Configuration → Advance Power Management Configuration → Power Performance Tuning [BIOS Controls EPB].
Configure ENERGY_PERF_BIAS_CFG Mode by navigating to Advanced → CPU Configuration → Advanced Power Management Configuration → ENERGY_PERF_BIAS_CFG Mode [Performance].
Set the Core Frequency (HWP)
wrmsr -a 0x774 0x2708
Identify Host Overhead¶
The following example shows the host overhead observed in a typical inference workload on PyTorch:
for query in inference_queries:
# Optional pre-processing on the host, such as tokenization or normalization of images
# Copy the result to device memory
query_hpu = query.to(hpu)
# Perform processing
output_hpu = model(query_hpu)
# Copy the result to host memory
output = output_hpu.to(cpu)
# Optional host post-processing, such as decoding
The model’s forward() function typically involves a series of computations. When executed without optimization,
each line of Python code in the forward() call is evaluated by the Python interpreter, passed through
the PyTorch Python front-end, then sent to the Intel Gaudi PyTorch bridge. Processing on the device only occurs when
mark_step is invoked or when the copy to the CPU is requested. See the illustration below.

The diagram indicates that the HPU will have extended periods of inactivity due to computation steps being dependent on each other.
To identify similar cases, use the Intel Gaudi integration with the PyTorch Profiler, see Profiling with PyTorch section. If there are gaps between device invocations, host overhead is impeding throughput. When host overhead is minimal, the device will function continuously following a brief ramp-up period.
The following are three techniques to lower host overhead and enhance your inference performance.
Use HPU Graphs¶
As described in Run Inference Using HPU Graphs, wrapping the forward() call in htorch.hpu.wrap_in_hpu_graph minimizes the time
in which each line of Python code in the forward() call is evaluated by the Python interpreter. See the example below.

Consequently, minimizing this time allows the HPU to start copying the output and running the computation faster, improving throughput.
Note
Using HPU Graphs for optimizing inference on Gaudi is highly recommended.
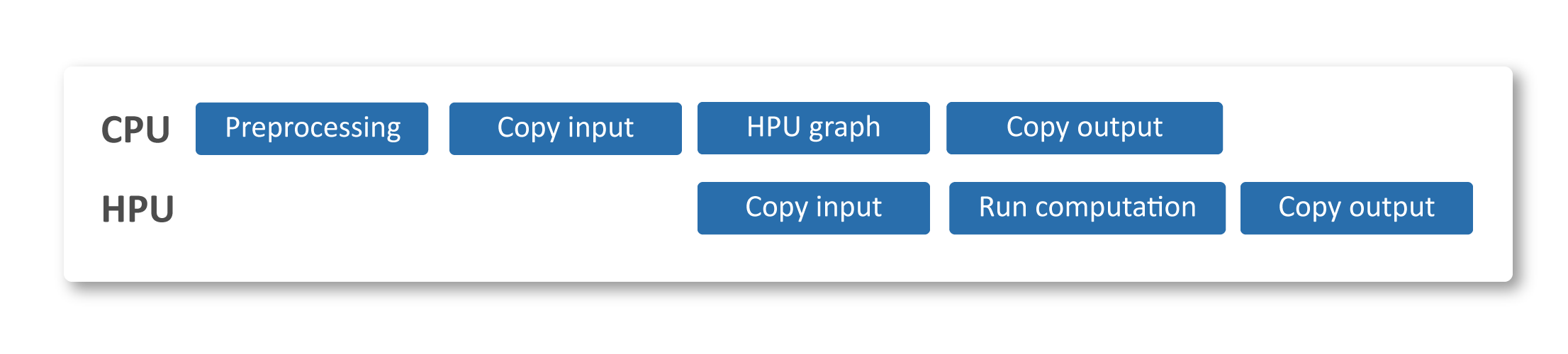
Use Asynchronous Copies¶
By default, the host thread that submits the computation to the device will wait for the copy operation to complete.
However, by specifying the argument non_blocking=True during the copy operation, the Python thread can
continue to execute other tasks while the copy occurs in the background.
To use Asynchronous Copies, replace query_hpu = query.to(hpu) with query_hpu = query.to(hpu, non_blocking=True).
See our Wav2vec inference example.
The following is an example of the timing diagram:
Note
Asynchronous Copies are currently supported from the host to the device only.
Use Software Pipelining¶
This section describes how to achieve software pipelining using threads. This method can be applied to models in which an inference request goes through several stages.
For each inference iteration, waiting for result and post-processing of results is dispatched on different threads. This allows each inference iteration to run as fast as possible without being blocked by result computation and post-processing. Since the different threads run in parallel, throughput is optimized depending on the latency of the slowest pipeline stage. An example of this method can be found in the Wav2Vec Model Reference on GitHub. Applying this to the Wav2Vec model utilized the device fully.
The following should be added to the inference model:
pool = multiprocessing.pool.ThreadPool(4)- Initializes a thread pool. It is common to align the number of threads with the number of pipeline stages. For example, Wav2Vec model uses two pipeline stages: tokenize + compute and then decode. However, in the Wav2Vec model twice that amount is used to have some leeway in scheduling and overcome random hiccups on the host side.logits_pinned.copy_(logits, non_blocking=True)- Utilizes a copy into pinned memory instead of regular memory. This allows the DMA on the device side to access the buffer.pool.apply_async(sync, args=(stream_obj, processor, logits_pinned, args, decodes, e2e, predicted, ground_truth, ds, r, i, tokens, perfs, perf_start))- In the original loop where software pipelining is not applied, the host thread blocks upon completion of the compute to copy back the results. Using software pipelining with the threads method defers this process to the thread pool. A thread is dispatched to perform the waiting, data copying, and decoding. Once the sample is done, the thread is returned to the pool.
The following is an example of the timing diagram in the steady state:
