Distributed Training across Multiple AWS DL1 Instances
On this Page
Distributed Training across Multiple AWS DL1 Instances¶
This document describes how to run distributed training workloads on multiple DL1 instances for AWS users. It includes distributed training support across various Intel® Gaudi® software releases, as well as how to configure workloads and instances for distributed training.
Distributed Training¶
Intel Gaudi supports distributed training across multiple servers over PyTorch. Cross-server communication is achieved through 400Gbs network connection between server hosts. Distributed training using Gaudi NICs across multiple servers is not offered in AWS. Instead, Host NICs are used for scaling across multiple instances. By default, DL1 instances get one Elastic Network Adapter (ENA) network interface. To receive better performance with libfabric, it is recommended to allocate DL1 instances with Elastic Fabric Adapter (EFA) network interfaces. DL1 instances support up to four network interfaces. For additional details on EFA usage and limitations, refer to EFA User Guide and EFA Limitations.
For PyTorch, only Distributed Data Parallel (DDP) is supported. Detailed information on distributed training across multiple servers (scale-out) and within a single-server (scale-up) can be found in Distributed Training with PyTorch.
Note
Having more than one EFA network interface prevents allocating a public IP address. To connect to the instance, one option is to assign an Elastic IP address.
Environment Variables for Different Implementations¶
AWS users can easily switch between different implementations by setting environment variables. The environment variables need to be set in all server instances during runtime. For further details, refer to PyTorch Scale-out Topology.
Running Distributed Training over Multiple DL1 Instances¶
An EFA requires a security group that allows all inbound and outbound traffic to and from the security group itself, similar to the below example. Follow the instructions in Prepare an EFA-enabled security group for more details.
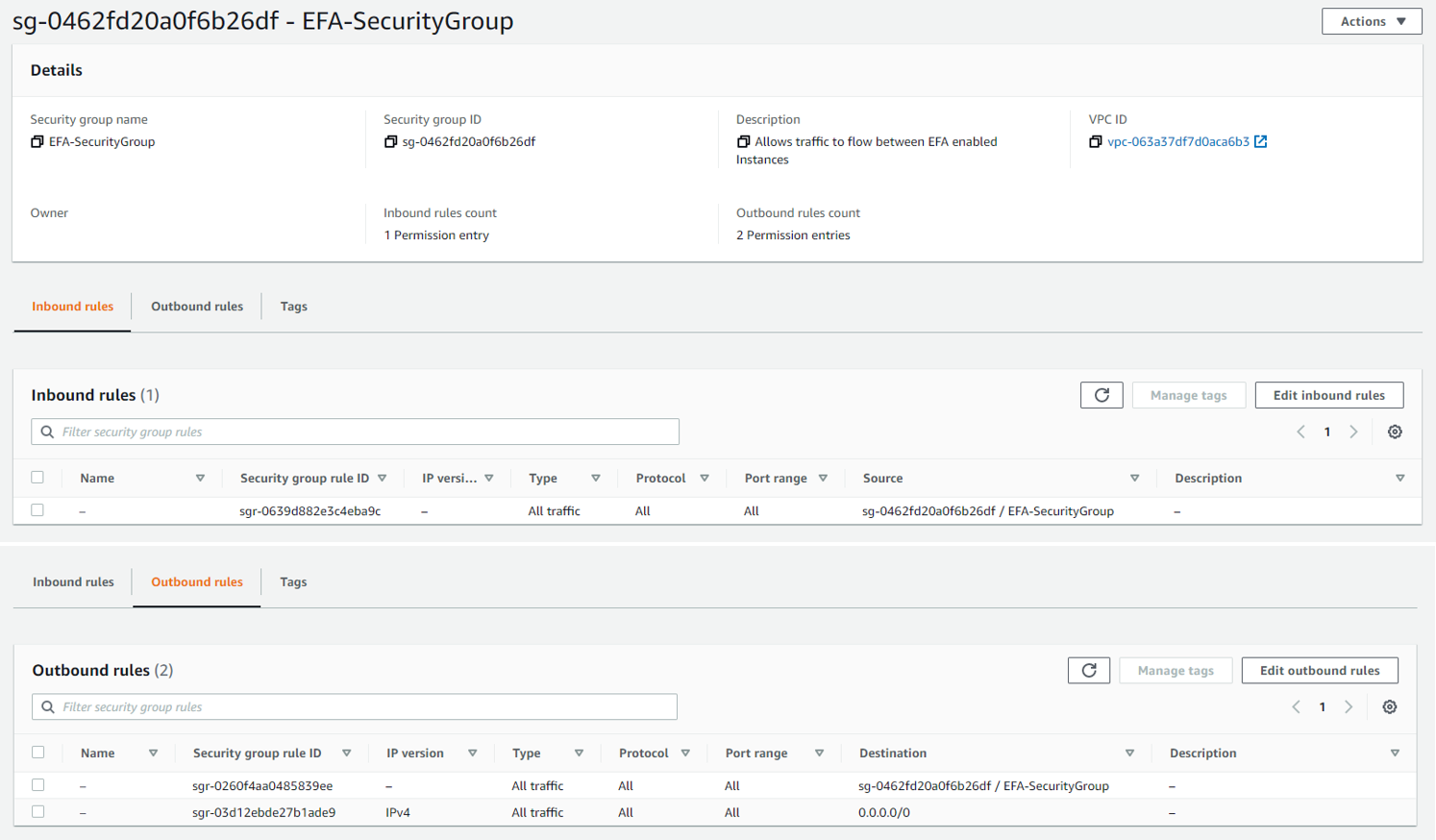
To launch multiple EFA-enabled DL1 instances, follow the instructions in Launch EFA-enabled instance.
Note
To run workloads on EFA-enabled AWS instances with Linux kernel lower than 5.13, the environment variable FI_EFA_FORK_SAFE must
be set to 1. It is required by Libfabric EFA provider to work safely with software utilizing fork(). However, on Linux kernel higher than 5.13 and rdma-core v35.0+, applications are always fork-safe where
setting this variable is not required.
Each instance needs to communicate with each other via SSH during training. To allow for instances to communicate, follow the below steps to enable passwordless SSH:
Disable
strictHostKeyCheckingand enableForwardAgent. Open~/.ssh/configusing your preferred text editor and add the following:Note
This step is not required when running in a container.
Host * ForwardAgent yes StrictHostKeyChecking no
Generate an RSA key pair:
ssh-keygen -t rsa -b 4096Change the permission of the private key:
chmod 600 ~/.ssh/id_rsa chmod 600 ~/.ssh/config
Copy the
generated id_rsa.pubcontent toauthorized_keysfor each node in the cluster:cat id_rsa.pub > authorized_keys
(Optional) Intel Gaudi PyTorch Dockers use port 3022 for SSH. This is the default port number configured in the training scripts respectively.
mpirunmight fail to establish the remote connection when there is more than one Intel Gaudi Docker session running. In this case, you need to set up a different SSH port. This can be done within the Docker by editing the file below and adding a different port number:sed -i 's/#Port 22/Port <my port number>/g' /etc/ssh/sshd_configThe below is an example using port 4022:
sed -i 's/#Port 22/Port 4022/g' /etc/ssh/sshd_configRestart sshd service within Docker:
service ssh stop service ssh start
The above steps need to be done for all instances. After that, you can verify the connectivity among instances by SSH from one instance to any other instance using the following command without being prompted for a key or password:
ssh -p 3022 10.232.192.227
Pull and Run Prebuilt Docker¶
Follow the steps below while running on Ubuntu 22.04.5.
Use the below command to pull Docker:
docker pull vault.habana.ai/gaudi-docker/1.21.3/ubuntu22.04/habanalabs/pytorch-installer-2.6.0:latest
Use the below command to run Docker:
docker run -it --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --net=host --ipc=host vault.habana.ai/gaudi-docker/1.21.3/ubuntu22.04/habanalabs/pytorch-installer-2.6.0:latest
Note
To run Intel Gaudi Dockers, make sure to include --device=/dev/infiniband/ for EFA usage.
Examples¶
You can find all steps to run distributed training across multiple servers using Host NICs in PyTorch ResNet50.