Theory of Distributed Training
On this Page
Theory of Distributed Training¶
From a hardware perspective, the Intel® Gaudi® AI accelerator supports the RoCEv2 RDMA over Converged Ethernet protocol. Each Gaudi natively integrates ten 100Gigabit Ethernet ports supporting RoCEv2. Fig. 4 shows a server which features eight Gaudi devices. Within each Gaudi device, seven of the ten NIC ports are used for connecting to the other seven Gaudis within the server in an all-to-all processor configuration for scale-up and three are used for scale-out across servers.
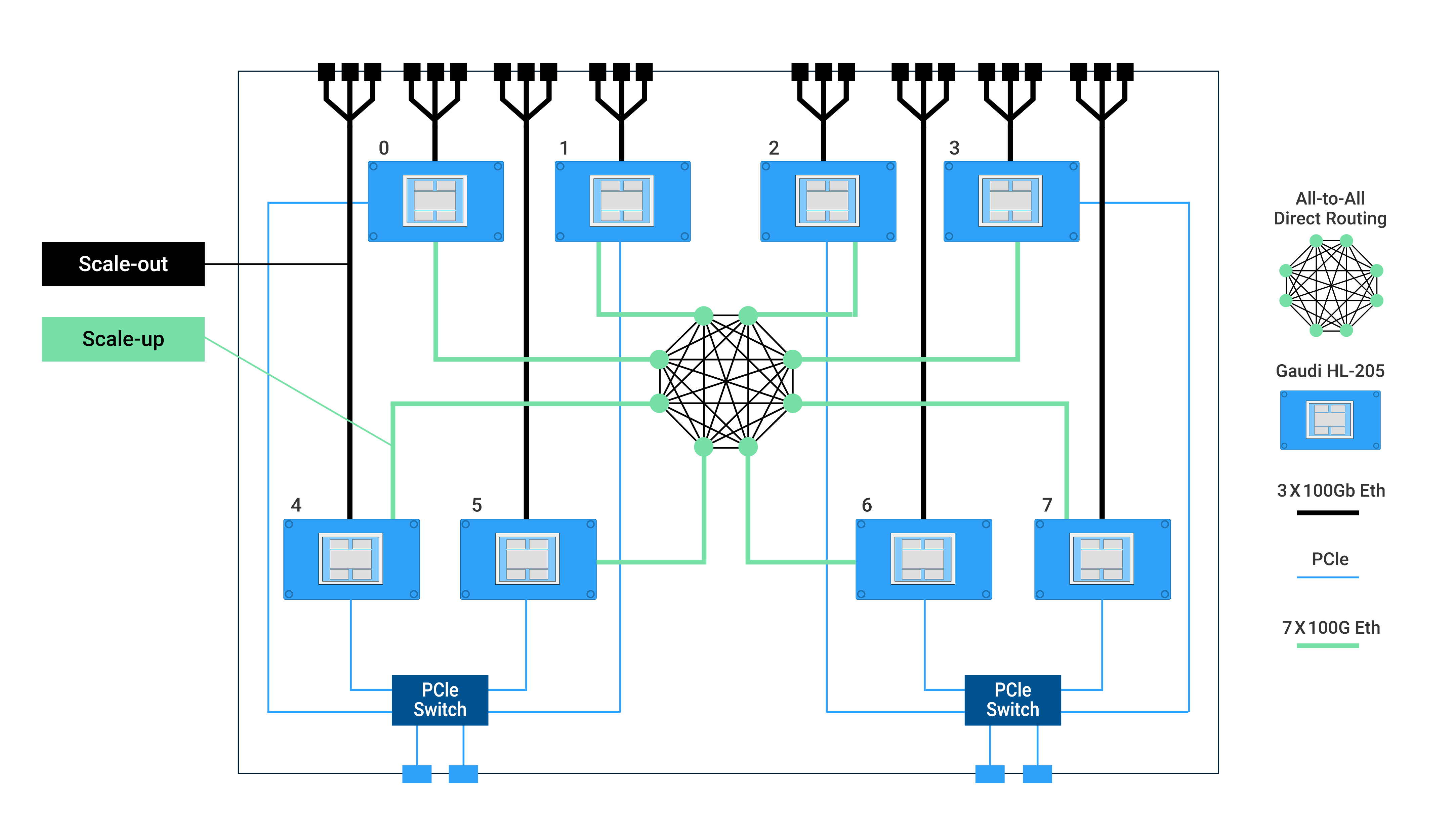
Figure 4 Server Block Diagram¶
Distributed Data Parallel - DDP¶
From a software perspective, Gaudi scaling with data parallelism in the PyTorch framework is achieved with torch.distributed package using DDP - Distributed Data Parallel
DDP is a widely adopted single-program multiple-data training paradigm. With DDP, the model is replicated on every process, and every model replica will be fed with a different set of input data samples. DDP takes care of gradient communication to keep model replicas synchronized and overlaps it with the gradient computations to speed up training.
In Fig. 5 DDP integration with HCCL is shown.
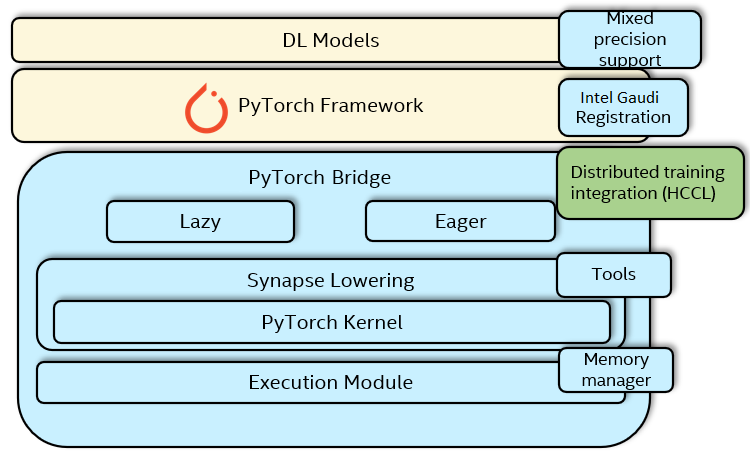
Figure 5 Gaudi Distributed Training Software Stack¶