Gaudi Architecture
On this Page
Gaudi Architecture¶
The Intel® Gaudi® AI accelerator architecture includes three main subsystems - compute, memory, and networking - and is designed from the ground up for accelerating DL training workloads.
The compute architecture is heterogeneous and includes two compute engines – a Matrix Multiplication Engine (MME) and a fully programmable Tensor Processor Core (TPC) cluster. The MME is responsible for doing all operations which can be lowered to Matrix Multiplication (fully connected layers, convolutions, batched-GEMM) while the TPC, a VLIW SIMD processor tailor-made for deep learning operations, is used to accelerate everything else.
Its heterogeneous architecture comprises a cluster of fully programmable TPC along with its associated development tools and libraries, and a configurable Matrix Math engine. The TPC core is a VLIW SIMD processor with instruction set and hardware tailored to serve training workloads efficiently. It is programmable, providing the user with maximum flexibility to innovate, coupled with many workload-oriented features, such as:
GEMM operation acceleration
Tensor addressing
Latency hiding capabilities
Random number generation
Advanced implementation of special functions
Gaudi architecture is the first DL training processor that has integrated RDMA over Converged Ethernet (RoCE v2) engines on-chip. These engines play a critical role in the inter-processor communication needed during the training process. This native integration of RoCE allows customers to use the same scaling technology, both inside the server and rack (scale-up), as well as to scale across racks (scale-out). These can be connected directly between Gaudi processors, or through any number of standard Ethernet switches.
Intel® Gaudi® 3 AI Accelerator¶
Gaudi 3 features two compute dies, which together contain 8 MME engines, 64 TPC engines and 24x 200 Gbps RDMA NIC ports. In addition, the total of 8 HBM2e chips comprise a 128 GB unified High Bandwidth Memory (HBM). The accelerator excels at training and inference with 1.8 PFlops of FP8 and BF16 compute, 128 GB of HBM2e memory capacity, and 3.7 TB/s of HBM bandwidth.
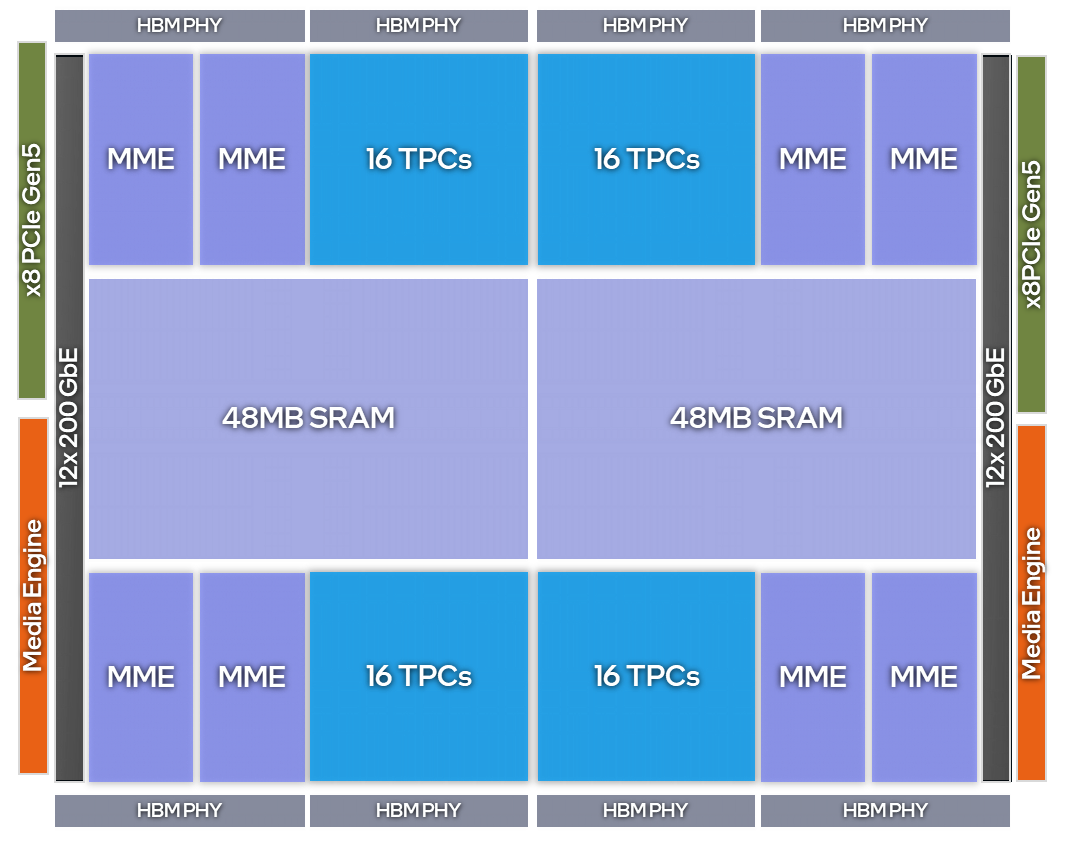
Figure 1 Gaudi 3 Processor High-level Architecture¶
Intel® Gaudi® 2 AI Accelerator¶
Gaudi 2 offers 2.4 Terabits of networking bandwidth with the native integration on-chip of 24 x 100 Gbps RoCE V2 RDMA NICs, which enable inter-Gaudi communication via direct routing or via standard Ethernet switching. The Gaudi 2 memory subsystem includes 96 GB of HBM2E memories delivering 2.45 TB/sec bandwidth, in addition to a 48 MB of local SRAM with sufficient bandwidth to allow MME, TPC, DMAs and RDMA NICs to operate in parallel.
Specifically for vision applications, Gaudi 2 has integrated media decoders which operate independently and can handle the entire pre-processing pipe in all popular formats – HEVC, H.264, VP9 & JPEG as well as post-decode image transformations needed to prepare the data for the AI pipeline.
Gaudi 2 supports all popular data types required for deep learning: FP32, TF32, BF16, FP16 & FP8 (both E4M3 and E5M2). In the MME, all data types are accumulated into an FP32 accumulator.
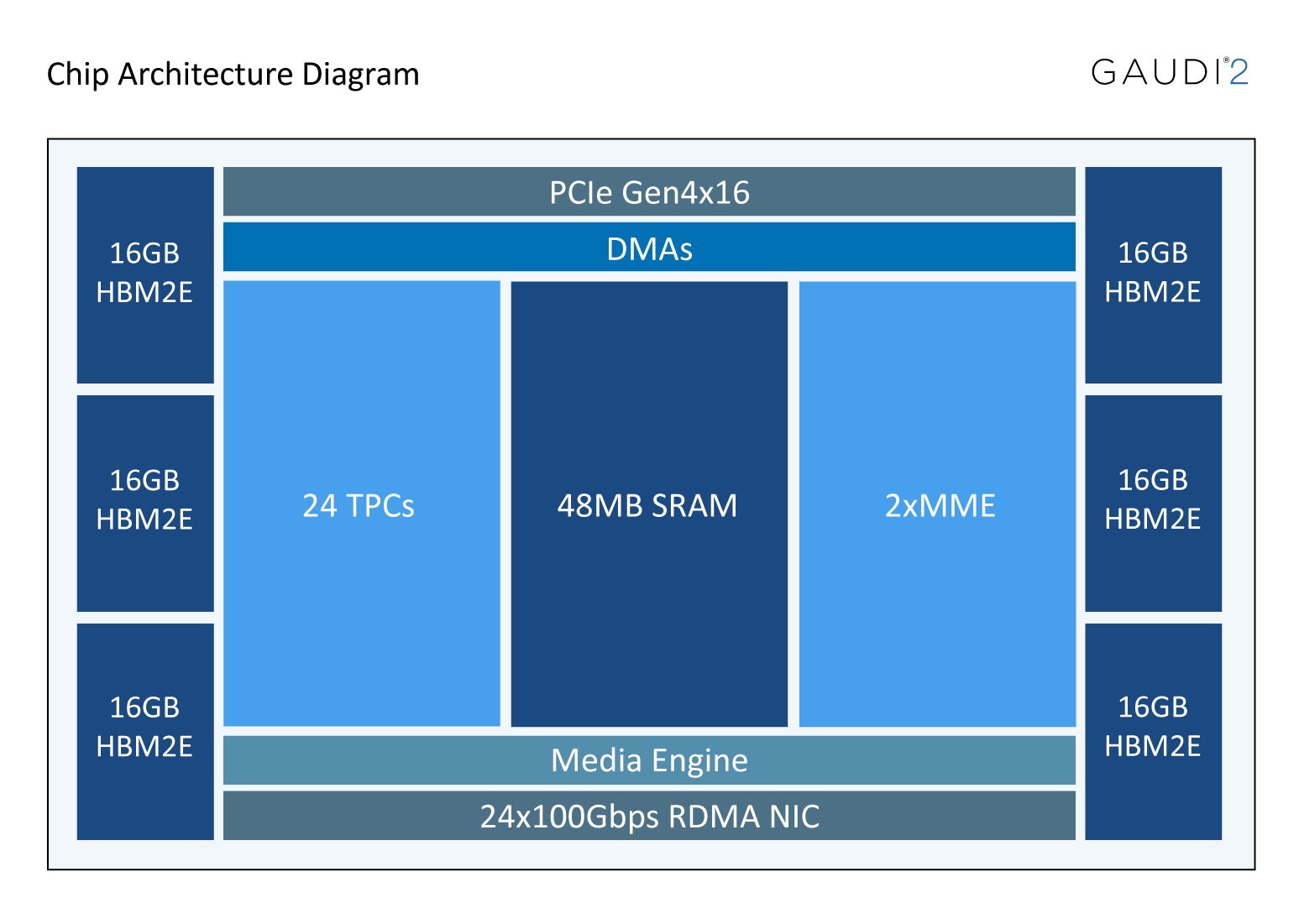
Figure 2 Gaudi 2 Processor High-level Architecture¶