PyTorch Gaudi Theory of Operations
On this Page
PyTorch Gaudi Theory of Operations¶
The Intel® Gaudi® PyTorch bridge interfaces between the framework and Intel Gaudi software stack enabling deep learning model execution on Gaudi devices. The following components are used to execute this integration:
Intel Gaudi installation package that provides a custom framework for interfacing with the Intel Gaudi PyTorch bridge as well as modifications to the PyTorch release.
habana_frameworks.torch.coremodule imported by the PyTorch scripts as described in Importing PyTorch Models Manually.
The Intel Gaudi PyTorch bridge supports multiple execution modes for PyTorch models.
Currently, Eager mode with torch.compile (if enabled), is the default execution path, while
Lazy mode is a legacy fallback that is no longer developed and will be deprecated in subsequent releases. It may still be used if the
model has compatibility issues with Eager mode and torch.compile or if certain performance
gains are only possible in Lazy mode. For more details, see Recommended Usage.
Execution Modes¶
The Intel Gaudi PyTorch bridge supports the following execution modes for a PyTorch model:
Eager Mode with
torch.compileextension (default) - Eager mode sends the ops for execution immediately, one-by-one, as defined in standard PyTorch Eager mode scripts. Thetorch.compileextension wraps a part of the model (e.g., a function) into a graph. Ops not wrapped in the graph are executed eagerly. Using torch.compile with Eager mode is recommended, as Eager mode alone can be slower due to its limited optimization of computation graphs.Lazy Mode (legacy) - Executes ops in a deferred manner, accumulating them into a graph. Lazy mode provides optimization for performance on Gaudi, but it comes with additional overhead of rebuilding the graph in each iteration. Lazy mode can be used as a fallback for models with compatibility issues or special performance requirements.
Note
For features supported for each execution mode, refer to PyTorch Support Matrix.
For a list of reference models verified to function with Eager mode and
torch.compileon Gaudi 3 and Gaudi 2, see Model References GitHub repository.
Recommended Usage¶
After porting a new PyTorch model to Gaudi, the following execution modes usage is recommended:
Start with Eager mode - Begin by ensuring your model functions in Eager mode. This approach is a recommended starting point after porting new models to Gaudi, as it requires minimal changes to existing code.
Optimize with one of the following graph solutions:
torch.compile- Once the model works correctly in Eager mode, optimize it by usingtorch.compile. This allows the entire model or parts of the model to be wrapped into a graph for more efficient execution. If the model does not currently usetorch.compile, it is highly recommended to attempt this optimization.Lazy mode - In case
torch.compileis not supported or very specific performance improvements are needed that only Lazy mode can achieve. Using the HPU Graphs feature with Lazy mode reduces host overhead as graphs are not rebuilt in each iteration. For more details, see HPU Graphs for Training and Run Inference Using HPU Graphs.
Use Lazy mode if it is already enabled in the model script. To ensure that Lazy mode is enabled, verify that
mark_stepis invoked and thePT_HPU_LAZY_MODE=1environment variable is set.Optimize with HPU Graphs - This feature reduces host overhead as graphs are not rebuilt in each iteration. For more details, see HPU Graphs for Training and Run Inference Using HPU Graphs.
Eager Mode¶
During Eager mode execution, the framework executes one op at a time from Python. The Intel Gaudi PyTorch bridge registers these ops for Gaudi device and drives the execution. It falls back to the CPU for any op that is not supported on the Gaudi device, then resumes the execution on Gaudi for supported ops.
Starting from v1.21.0 release, Eager mode is enabled by default.
Note
Eager mode requires that all ops are executed immediately, one at a time. As a result, tensors cannot reside on different devices (e.g., HPU (hpu:0) and CPU) without explicit movement of one tensor to the HPU for efficient computation.
When running vision models in Eager mode (e.g., ResNet, ResNeXt, UNet2D, UNet3D), set the
PT_HPU_EAGER_ENABLE_GRADIENT_VIEW_LAYOUT_OPT=1flag to optimize performance during execution.
torch.compile Extension¶
torch.compile, introduced in PyTorch 2.0, allows to wrap parts of a model into a graph for improved performance.
Model parts wrapped with torch.compile are compiled once at the start, allowing the compiled part to be called throughout execution.
However, parts without such wrapping run in pure Eager mode, executing each op individually, affecting overall performance.
Unlike Lazy mode, Eager mode with torch.compile does not require rebuilding a graph in each iteration which reduces host computation overhead.
When using this mode, the model script requires additional changes pointing to the parts which need to be treated as part of torch.compile.
See torch.compile documentation and
torch.compile tutorial for more details.
The below shows an example of MNIST extended to use torch.compile:
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
model = torch.compile(model,backend="hpu_backend")
def train_function(data, target):
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
return loss
training_step = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
loss = train_function(data, target)
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx *
len(data), len(train_loader.dataset)/args.world_size,
1. * batch_idx / len(train_loader), loss.item()))
if batch_idx != 0 and args.dry_run:
break
if args.max_training_step != 0:
training_step +=1
if training_step == args.max_training_step:
break
The backend parameter must be set as hpu_backend for both training and inference.
Lazy Mode¶
With this mode, users retain the flexibility and benefits that come with the PyTorch define-by-run approach of the Eager mode. The Intel Gaudi PyTorch bridge internally accumulates ops into a graph, executing them lazily - only when a tensor value is needed by the user. This approach allows the bridge to construct a graph of multiple ops, enabling the Intel Gaudi graph compiler to optimize the execution of these ops.
Starting from v1.21.0 release, Lazy mode is not the default execution path. It can be enabled with the PT_HPU_LAZY_MODE=1 environment variable if necessary. This flag must be
set before importing habana_frameworks.torch in your script.
This mode will be deprecated in subsequent releases.
Public PyTorch Support¶
The Intel Gaudi PyTorch bridge is compatible with both Intel Gaudi PyTorch fork
and public PyTorch 2.10.0. This dual support is provided within a single wheel package,
with the bridge dynamically detecting whether the public PyTorch or Intel Gaudi PyTorch fork is installed.
Support for public PyTorch is currently in preview mode, limited to Eager
mode with torch.compile, and does not include a dedicated Docker image.
Eager mode with torch.compile can still be used with Intel Gaudi PyTorch fork while Lazy mode is
compatible only with Intel Gaudi PyTorch fork.
Public PyTorch packages can be installed in release Docker using the following command:
pip install torch torchvision torchaudio torchtext torchdata --index-url https://download.pytorch.org/whl/cpu
This command automatically overrides extra packages compiled for Intel Gaudi PyTorch fork.
Starting from v1.22.0, Intel Gaudi PyTorch fork and the public PyTorch use the same setting of the _GLIBCXX_USE_CXX11_ABI flag, which
set to 1 - the default value for PyTorch packages available on public repositories such as pypi.
Any libraries or packages previously compiled with _GLIBCXX_USE_CXX11_ABI=0 must be recompiled with _GLIBCXX_USE_CXX11_ABI=1 to ensure compatibility.
This update replaces the previous setting in v1.21.x (_GLIBCXX_USE_CXX11_ABI=0) and aligns with the corresponding update in public PyTorch.
The below table summarizes the supported settings:
Intel Gaudi PyTorch Fork |
Public PyTorch |
|
|---|---|---|
Lazy mode |
Supported |
Not supported |
Eager mode with |
Supported |
Supported |
Public PyTorch packages |
Supported |
Supported |
ABI flag |
1 |
1 |
Intel Gaudi PyTorch Bridge¶
This section describes the major components of the Intel Gaudi PyTorch bridge. The architectural diagram for the PyTorch Intel Gaudi full stack including the Intel Gaudi PyTorch bridge components is shown in the below figure.
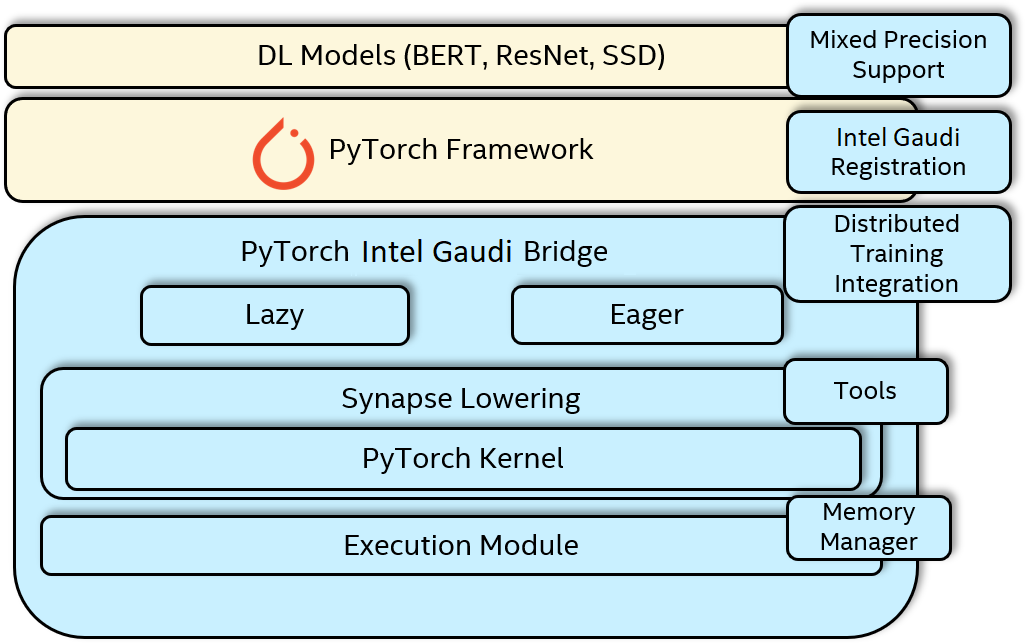
Figure 6 PyTorch Intel Gaudi Full Stack Architecture¶
Intel Gaudi Software Lowering Module¶
The Lowering module converts the framework provided op or graph to Intel Gaudi software. The PyTorch framework dispatches the execution
to the registered methods in the Intel Gaudi PyTorch bridge when an op is invoked on Intel Gaudi tensors. In Eager mode with torch.compile and Lazy mode, the Intel Gaudi bridge internally
builds a graph with accumulated ops. Once a tensor is required to be evaluated, the associated graph that needs to be executed is
identified for the resulting tensor. Various optimization passes are applied to the graph, such as:
Fusion of ops that are beneficial for Gaudi.
Optimal placement of permutations for channel last memory format of tensors.
Identification of persistent, non-persistent and tensors with duplicate or aliased memory.
PyTorch Kernels¶
The PyTorch kernel module within the Intel Gaudi PyTorch bridge provides the functionality to convert a PyTorch op into appropriate Intel Gaudi software ops. The PyTorch op could be implemented with a single or multiple TPC/MME ops. The PyTorch kernel module adds these set of software ops to the graph and converts the PyTorch tensors to Intel Gaudi tensors for building the Intel Gaudi graph.
Execution Module¶
The Execution module in the Intel Gaudi PyTorch bridge provides the functionality to compile an Intel Gaudi graph and launch the resulting recipe in an asynchronous method. The recipes are cached by the Intel Gaudi PyTorch bridge to avoid recompilation of the same graph. This caching is done at an eager op level as well as at a JIT graph level. During training, the graph compilation is only required for the initial iteration, thereafter, the same compiled recipe is re-executed every iteration (with new inputs) unless there is a change in the ops being executed.
Memory Manager¶
The Intel Gaudi PyTorch bridge has a memory manager that optimally serves the allocation and free requests from the device memory. It additionally provides the capability to create tensors with pinned memory, which reduces the time required for doing a DMA by avoiding a copy on the host side. The pinned memory feature can be expressed on a tensor with existing flags provided by the PyTorch framework.
Huge Pages Usage¶
To enhance memory pinning capabilities and improve host-side DMA buffer management, the Intel Gaudi PyTorch bridge uses huge pages available in the system by default. Huge pages are a Linux kernel feature that enables more efficient memory handling. For more details and configuration options, see Linux kernel documentation.
When allocating host-side DMA buffers or pinned memory, the Intel Gaudi PyTorch bridge first attempts to use 2MB huge pages. If they are not available, it falls back to standard 4KB pages. It uses both regular and surplus 2MB huge pages.
By default, the total available pool of huge pages is split equally among all Gaudi devices in the system to ensure equal access and prevent any device from running out of memory, assuming no other process heavily consumes huge pages.
In cases where a specific workload requires uneven distribution of pinned memory
(e.g., one process needs significantly more than others), this default behavior can
be overridden per process using the PT_HPU_HUGE_PAGES_LIMIT_MB environment variable.
Usage examples:
PT_HPU_HUGE_PAGES_LIMIT_MB=1024- restricts huge page usage to 1GB for the process, instead of relying on the system configuration and dividing the available memory between the devices.PT_HPU_HUGE_PAGES_LIMIT_MB=1- effectively disables huge page usage, as the minimum allocation via huge pages is 2MB.
Note
Other components of the Intel Gaudi software may also use huge pages. This configuration and behavior apply only to the Intel Gaudi PyTorch bridge.
Mixed Precision Support¶
Gaudi supports mixed precision training using PyTorch autocast. Autocast is a native PyTorch module that allows running mixed precision training without extensive modifications to existing FP32 model script.
It executes operations registered to autocast using lower precision floating datatype.
The module is provided using the torch.amp package.
For more details on PyTorch autocast, see Mixed Precision Training with PyTorch Autocast.
Distributed Training¶
Intel Gaudi PyTorch implements HCCL communication backend to support scale-up and scale-out. See Distributed Training with PyTorch.
Intel Gaudi Media Loader¶
habana_dataloader is an accelerated dataloader which can operate in different modes. The optimal one is selected based on the underlying hardware where,
in Gaudi 2, the dataloader uses hardware-based decoders for acceleration, lowering the load on the host CPU. For further details on habana_dataloader
setup and usage, refer to Intel Gaudi Media Loader.
The habana_dataloader inherits the native torch.utils.data.DataLoader and maintains the same
interface from the user perspective. Internally, habana_dataloader falls back to the
native torch data loader if the provided parameters are not supported.
The dataloader is imported and used similar to the torch DataLoader. For example:
import habana_dataloader
habana_dataloader.HabanaDataLoader(
dataset, batch_size=args.batch_size, sampler=train_sampler,
num_workers=args.workers, pin_memory=True, drop_last=True)
The following are full examples of models using habana_dataloader with PyTorch: