Intel Gaudi Software Suite
On this Page
Intel Gaudi Software Suite¶
Designed to facilitate high-performance DL training on Intel® Gaudi® AI accelerators, the Intel Gaudi software enables efficient mapping of neural network topologies onto Gaudi hardware. The software includes graph compiler and runtime, TPC kernel library, firmware and drivers, and developer tools such as the TPC SDK for custom kernel development and Profiler. The Intel Gaudi software is integrated with PyTorch, and performance-optimized for Gaudi. Fig. 3 shows the components of the Intel Gaudi software suite.
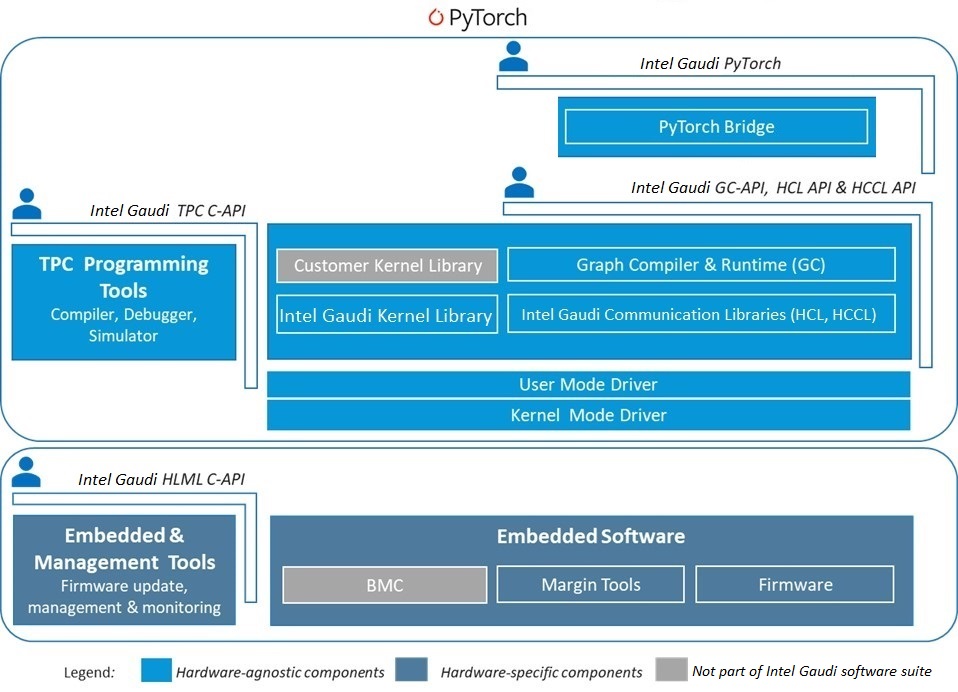
Figure 3 Intel Gaudi Software Suite¶
Note
To install the Intel Gaudi software, refer to the Installation Guide.
Graph Compiler and Runtime¶
The Intel Gaudi graph compiler generates optimized binary code that implements the given model topology on Gaudi. It performs operator fusion, data layout management, parallelization, pipelining and memory management, as well as graph-level optimizations. The graph compiler uses the rich TPC kernel library which contains a wide variety of operations (for example, elementwise, non-linear, non-GEMM operators). Kernels for training have two implementations, forward and backward.
Given the heterogeneous nature of Gaudi hardware (Matrix Math engine, TPC and DMA), the Intel Gaudi graph compiler enables effective utilization through parallel and pipelined execution of framework graphs. The Intel Gaudi software uses stream architecture to manage concurrent execution of asynchronous tasks. It includes a multi-stream execution environment supporting Gaudi’s unique combination of compute and networking as well as exposing a multi-stream architecture to the framework. Streams of different types — compute, networking and DMA — are synchronized with one another at high performance and with low runtime overheads.
Habana Collective Communication Library¶
The Intel Gaudi software suite includes Habana Collective Communications Library (HCCL) which is Intel Gaudi’s implementation of standard collective communication routines with NCCL-compatible APIs. HCL uses Gaudi integrated NICs for both scale-up and scale-out. HCCL allows users to enable Gaudi integrated NIC for scale-up and Host NIC for scale-out. See Habana Collective Communications Library (HCCL) API Reference for further details.
TPC Programming¶
The Intel Gaudi TPC SDK includes an LLVM-based TPC-C compiler, a simulator and debugger. These tools facilitate the development of custom TPC kernels. This SDK is used by Intel Gaudi to build the high-performance kernels we provide to users. You can thereby develop customized deep learning models and algorithms on Gaudi to innovate and optimize to your unique requirements.
The TPC programming language, TPC-C, is a derivative of C99 with added language data types that enable easy utilization of processor-unique SIMD capabilities. It natively supports wide vector data types to assist in programming the SIMD engine (for example, float64, uchar256 and so on). It has many built-in instructions for deep learning, including:
Tensor-based memory accesses
Accelerations for special functions
Random number generation
Multiple data types
A TPC program consists of two parts – TPC execution code and host glue code. TPC code is the ISA executed by the TPC processor. Host code is executed on the host machine and provides specifications regarding how the program input/outputs can be dynamically partitioned between the numerous TPC processors in the Gaudi device.
For more details, refer to the following:
DL Framework Integration¶
Popular DL framework PyTorch is integrated with Intel Gaudi software and optimized for Gaudi. The Intel Gaudi software does this under the hood, so customers still enjoy the same abstraction in PyTorch that they are accustomed to today. The Intel Gaudi PyTorch bridge identifies the subset of the framework’s computation graph that can be accelerated by Gaudi. These subgraphs are executed optimally on Gaudi. For performance optimization, the compilation recipe is cached for future use. Operators that are not supported by Gaudi are executed on the CPU.
For more details, refer to PyTorch.