Fully Sharded Data Parallel (FSDP) Theory of Operations
On this Page
Fully Sharded Data Parallel (FSDP) Theory of Operations¶
FSDP enables data parallelism training through the following steps:
Init step - Full parameter sharding, where only a subset of the model parameters, gradients, and optimizers is needed for a local computation.
Forward step:
All weights are locally gathered from the Gaudi devices with allgather.
Forward pass is calculated.
The allgather is done again before before the backward pass.
Backward step:
Backward pass is calculated.
The local gradients are averaged and sharded across the Gaudi devices with reduce_scatter. This allows each Gaudi to update its local weight shard.
DDP and FSDP¶
The below image demonstrates standard data parallel training and fully sharded data parallel training processes.
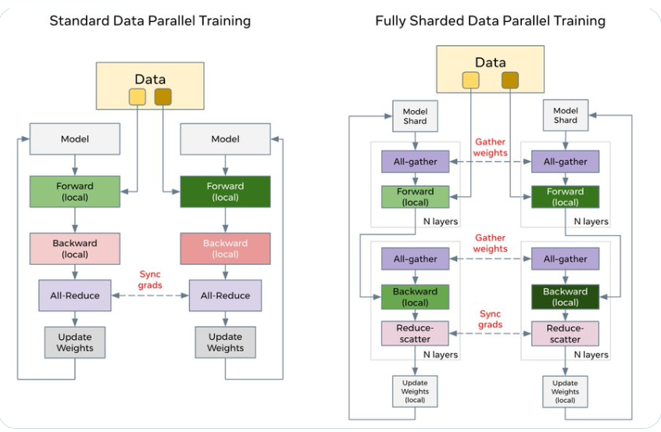
DDP and FSDP Flows¶
In DDP, each device holds a full copy of the model, computing on a shard of data before sharing parameters globally. By using allreduce, it sums gradients across workers and distributes them equally.
FSDP distributes only parts of the model across Gaudis, with weights gathered before both forward and backward passes, enabling localized weight updates.
In FSDP, allreduce is broken down into reduce_scatter and allgather. During the backward pass, it reduces and scatters gradients across ranks. Then it updates the respective shard of the parameters. In subsequent forward pass, FSDP performs allgather to collect and combine updated parameter shards.
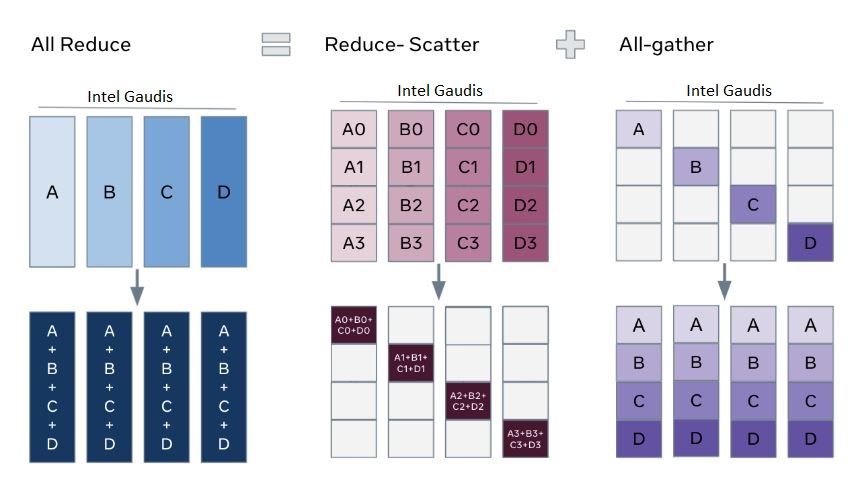
FSDP Allreduce¶